I Switched My Local Copilot From llama.cpp to vLLM — 2× VRAM for 50% Faster Completions
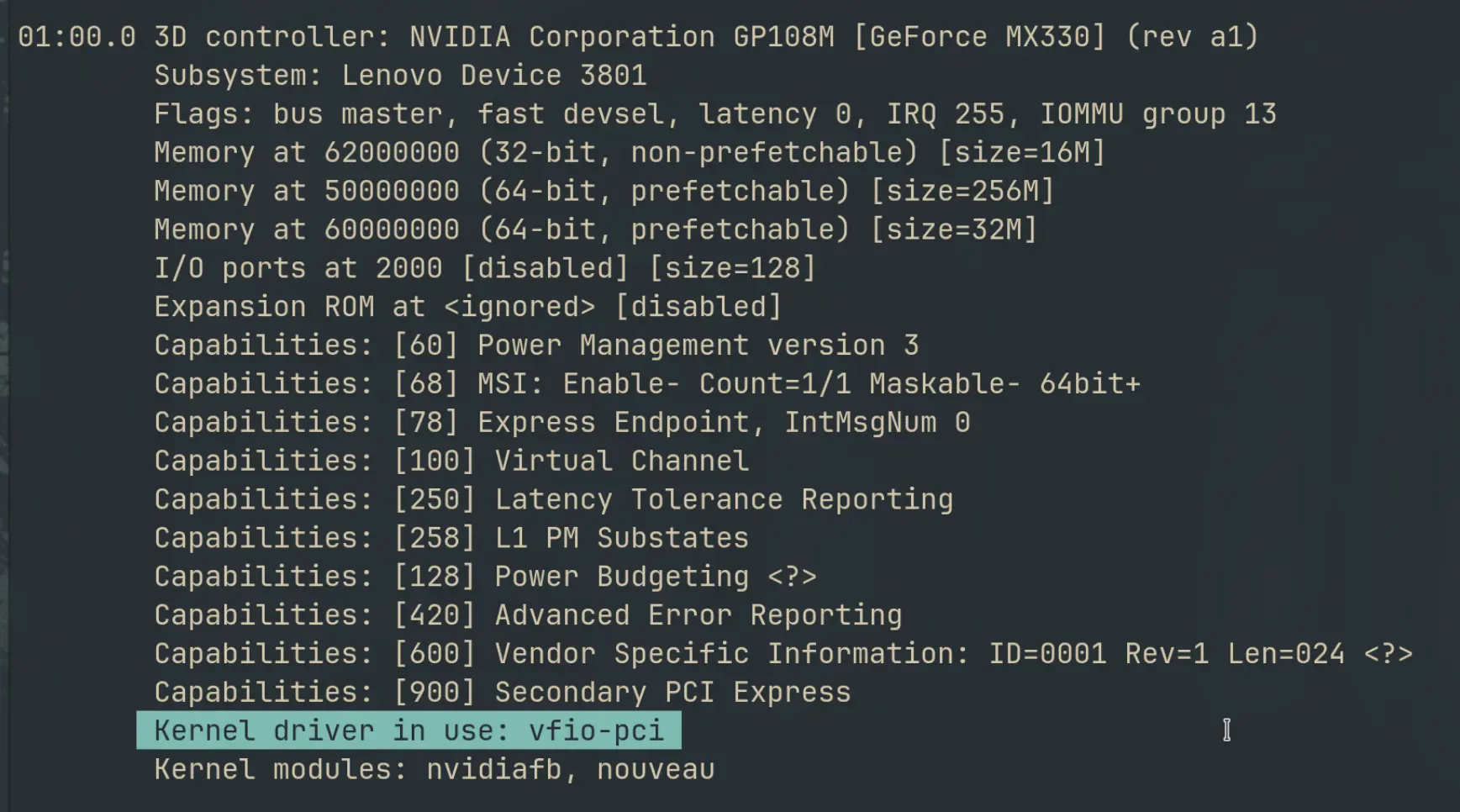
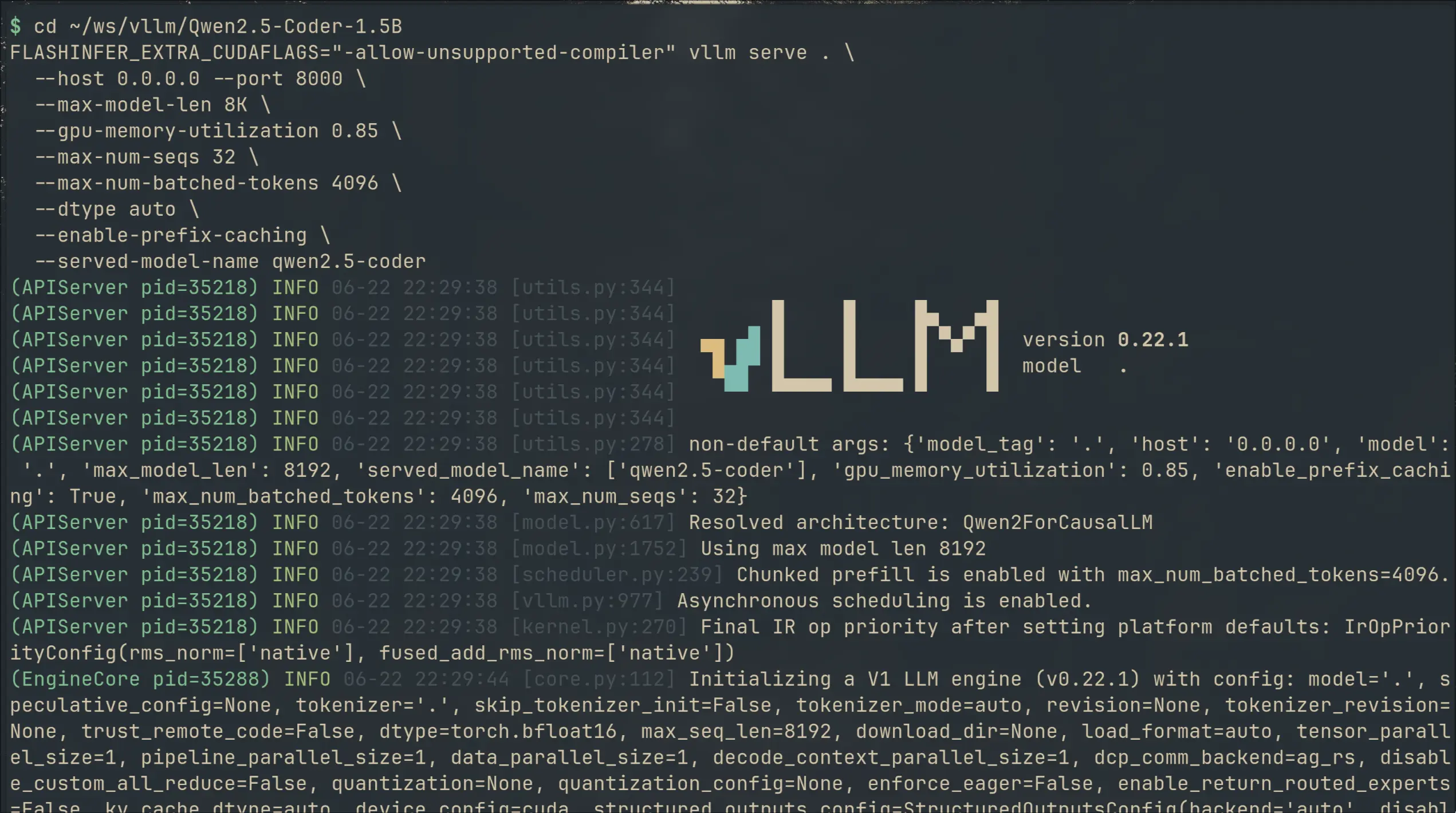
↗I swapped llama.cpp for vLLM on my local code completion setup. 49% faster generation, 36% lower latency — but 2× the VRAM. Here's what I gained, what it cost, and the gritty install details.